Neuro-Inspired Computing for the Internet of Things
Prof. Rabaey from UC Berkely explains how the future of computing could be inspired by the human brain.

Recently Maxim Integrated hosted an IEEE talk by prof. Jan Rabaey on Neuro-Inspired Computing. The talk highlighted the challenges of traditional computing and provided an overview of a possible neuro-inspired solution.
Trends in computing
It is evident to anyone that we are generating more and more data per capita than ever before. Think about all the photos we take with smartphones, the data stored in the cloud or the plethora of web/mobile apps we use on a daily basis. This trend isn’t ending anytime soon; if anything, the pace at which data is generated is just getting faster and faster with more people connecting to the internet and the advent of the Internet of Things (IoT) where all objects are expected to communicate with the cloud.
How is the current computing infrastructure going to evolve to handle this? Are we going to simply use next year’s faster computers? Is anything else needed?
State of digital electronics
The famous Moore’s law predicts that the number of transistors per square inch in integrated circuits roughly doubles every year. Look at the green curve on the chart, that rule certainly seems to be true. Now, what’s going on with the clock speed and power curves? Traditionally, higher transistor density in microprocessors was achieved by reducing the size of the transistor itself. A transistor is, to simply put it, an electronic switch made of silicon. Intuitively, making it smaller should allow turning it on and off faster (read higher clock frequency) and with less effort (read lower energy/power dissipation per operation). All this worked wonderfully throughout the ‘90s, but it is clear from the chart that somehow the trends stopped in the early 2000s. Around 2004 transistors became so small that making them work well and accurately became very very difficult, mostly due to limits dictated by physics. Such small transistors were difficult to reproduce accurately and started to leak current, which prevented CPUs to increase their clock frequency without getting extremely hot. This is obviously an oversimplification of what happened, many other factors came into play that are not mentioned here, but you get the idea of the problems the engineering community faced.
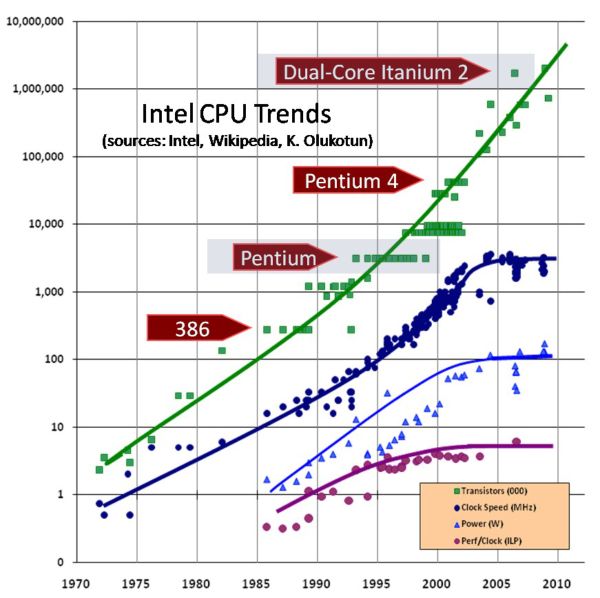
To mitigate the issue, engineers have come up with a clever workaround solution: instead of focusing on increasing the speed of a single CPU, why not having two slower microprocessors working in parallel? If you could make a piece software evenly distribute its operations across two CPUs you would effectively run it at twice as much the speed! This is why, starting from the mid 2000s, we stopped seeing faster CPUs and the era of multi-core microprocessors officially started. Unfortunately, there is only so much code that can be run in parallel for any given software, and the benefits of multi-core approaches plateau pretty quickly with increased number of parallel cores. In order to keep increasing computing capabilities a radically different approach might be needed.
Taking inspiration from the brain
The brain is an exceptional computing machine: it’s 2-3 orders more efficient than today’s silicon equivalent, it’s highly robust (we lose neurons every day, but still keep functioning pretty well) and has amazing performances using a huge number of mediocre components (we have about 86 billion neurons with high variability in response strength and speed). How does the brain perform so well with such an architecture? Can we replicate the brain’s architecture using these new extremely small but highly variable nano-transistors?
An interesting example to look at is the way the brain (computing system) works with the eye (the sensor) to help us distinguish objects that are in our field of view. In the picture below, the eye-to-brain sensory chain is schematically represented.
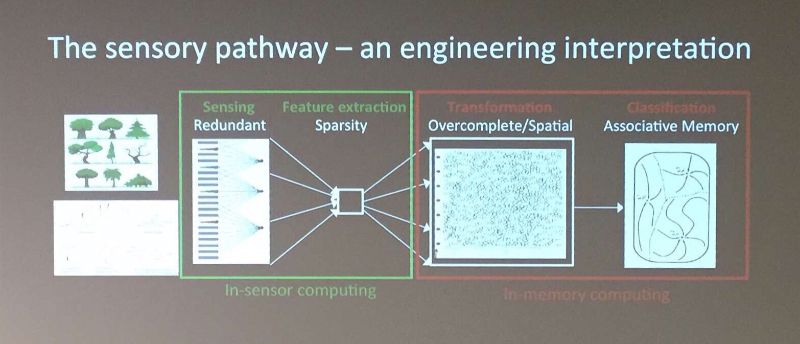
We can recognize two main sections:
- In the first section, the eye first acquires raw data and then executes a feature extraction to remove all the non-necessary information. This pre-processing operation is key to prevent overloading the computing system. If this wasn’t done, we would need a much larger and higher-bandwidth optical nerve to connect the eye to the brain, and the brain would have to execute much more complex algorithms to help us distinguish objects. It is easy to make an analogy between this and the “fog computing” paradigm of IoT (see older blog post).
- In the second section, data is transferred to the brain where millions of neurons take care of comparing the extracted features with a database of known shapes to associate meaning to everything we see.
For each operation the brain performs, millions of neurons are involved. One of the reasons for this is robustness: by not having single neurons dedicated to single functions the brain can figure things out despite having many neurons firing the wrong answer, having a signal too small to be correctly distinguish from the noise, or simply not working. Neurons look incredibly similar to modern nano-electronic devices which are small, fast but highly variable. Can we mimic the brain’s approach to computation with a silicon implementation?
Data representation as the key factor
Prof. Rabaey thinks that the key of brain’s computing process is data representation. Today, data is stored in computers using strings of bits grouped into fields containing different pieces of information. Error correction algorithms allow to tolerate some errors, but if the number of mistakes is too high, data will get lost. Because every bit of information counts, we need to design circuits using electronics that is highly reliable and have low variability. Given that it’s not possible to make identical transistors, engineers design circuits taking margins and also discard all the chips that don’t meet the wanted specifications. This is not an efficient or economic solution: it is easy to understand that, as transistors variability increases, the margining we need to use in design ultimately limits the maximum achievable performance and the minimum cost per chip. At some point, prof. Rabaey urged, we need to start embracing the variability of nano-devices instead of fighting it: we need to move away from a form of computing that is deterministic, and develop statistical computing solutions that can tolerate a wider range of errors while still returning good answers. Note that I did not say “correct” answers. A statistical computing system wouldn’t be suitable to solve any possible problem, but could nicely address those of statistical nature (where a correct answer does not exist, or is not required) such as most of the applications involving the interaction with the environment (e.g. distinguishing objects, searching for a matching web-page and many applications of the Internet of Things).
The idea in a nutshell
The idea prof. Rabaey proposed is to use an hyperdimensional representation of the data which, in simple words, means representing data with way more bits than needed (for instance using a 10,000 bit vector to store few bytes of information). In a nutshell it is possible to show that random hyperdimensional arrays/vectors have subtle properties suitable to be the base a new kind of computing. Hyperdimensional vectors are also an incredibly robust representation of information, able to tolerate a large number of errors and still maintain the data integrity intact.
The basic idea is to assign random 10,000-ish bit vectors to each data element and variable to be stored. Multiple data points can then be combined in a single 10,000 bit vector by simple arithmetic calculations. The new vector will contain all the information combined and spread across all its bits in a full holistic representation so that no bit is more responsible to store any piece of information than another. These random vectors are then used with associative memories to execute complex computations (see an example in the picture below).

This architecture and data representation is inherently robust, thrives on the randomness and variability of the computing elements and, obviously, requires large array of memory to work. The idea matches quite well with the capabilities and, above all, the limits of the silicon nano-devices of today and the future. Scientists have already shown neuro-inspired systems performing many brain-like type of tasks such as understanding by analogy, recognizing images and understanding the figurative/indirect meaning of text using algorithms that are much simpler and efficient than what currently used for similar tasks in traditional deterministic computing systems.
All this is really exciting and promising, who knows when (if ever) we will be able to see these concepts applied outside of scientific papers.